Week 14 — Study critique and design-memo workshop
Turning a design critique into a clear, evidence-bounded memo
Concept note
This is a workshop week, not a new-machinery week. Everything you need is already on the table — you have spent thirteen weeks learning to tell random sampling from random assignment, to spot a confounder, to read a factorial cell instead of a lone main effect, and to bound nonresponse instead of assuming it away. The job this week is to put those moves together into a single repeatable act: take a one-line claim that somebody is making about a study, critique it as a design, and rewrite it as a short, honest, evidence-bounded design memo. This is the final design project in miniature, run on the three studies you already know cold.
A good critique is not a list of complaints and it is not “the sample was too small.” A good critique follows a fixed skeleton, and the skeleton is the course:
- Claim — what is actually being asserted? Strip the marketing. Is it a population claim (“45% of undergraduates get adequate sleep”) or a causal claim (“the center works”)? Those need different designs to earn them, so naming the claim type is the first fork.
- Unit of analysis — what entity does a row of data describe, and is that the entity the design sampled or assigned? A claim about students built on data assigned at the dorm-floor level is already in trouble before any number is computed.
- Design — was anything sampled at random (which would earn a population claim), was anything assigned at random (which would earn a causal claim), both, or neither? This single question does more work than any other. Random sampling and random assignment are independent design choices; a study may have one, both, or neither, and confusing the two is the most common failure on this page.
- Threats to validity — what could make the number wrong for the claim? Confounding, selection bias, measurement error, nonresponse, attrition, a bad control adjusted in by accident, a coverage gap in the frame. Name the specific threat, not “bias” in the abstract.
- What the data support — given the design, what claim is licensed? State it in the narrowest defensible form, with the assumptions it rests on made explicit.
- What would strengthen it — the constructive half. What one change to the design — randomize the exposure, measure the missing confounder, follow up the nonrespondents, raise the response rate — would let the claim be made more strongly?
The design memo is the written product of that skeleton. It says, in plain prose, what the study supports, what it does not, and what additional evidence would move the claim forward. The memo is where the course’s whole ethic lives: software output does not rescue a weak design, and a confident sentence does not either. The memo’s discipline is to make the claim no larger than the design can carry.
Two traps haunt this week specifically. The first is overclaiming external validity (Risk 13) — taking a result that holds for the sampled population and quietly stretching it to everyone. A survey of one campus’s email list speaks to that campus’s emailed students, not to “college students.” The second is drawing a causal arrow the design cannot support (Risk 15) — writing “the center raised scores” when all you have is an observational gap between people who chose to use it and people who did not. The memo’s job is to refuse both stretches, on the page, in writing.
Setup and practice sequence
Work this as a numbered sequence. You can do it on paper, in a spreadsheet, or in a .qmd file — the static R below shows the arithmetic so your memo’s numbers are anchored to the locked study values, not invented at the keyboard. Each step is ungraded practice; treat the “your turn” prompts as self-checks.
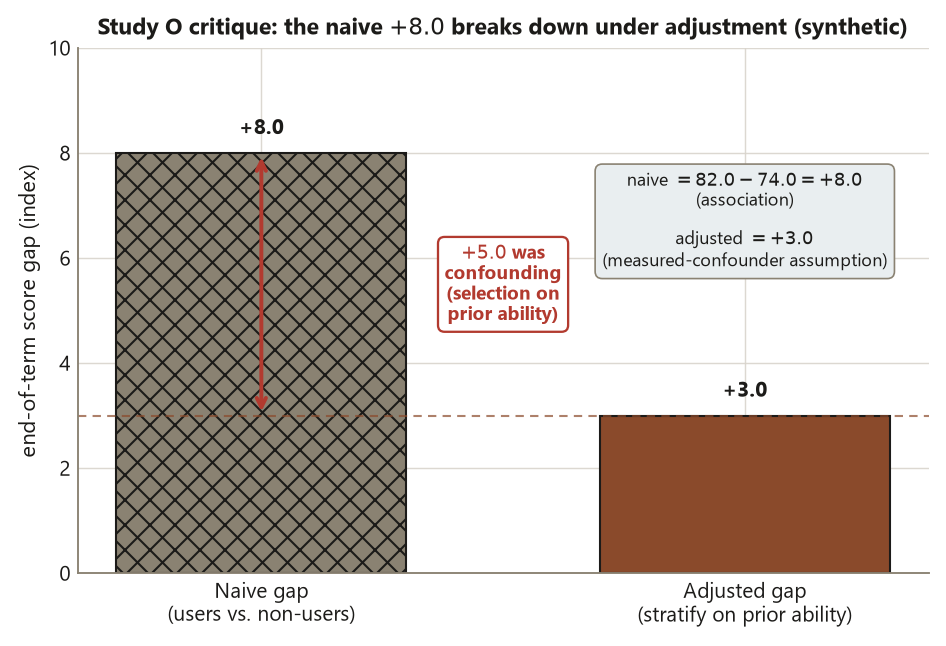
Capture the raw claim, verbatim. Write the one-liner exactly as someone would say it. For Study O that is: “Students who used the tutoring center scored 8 points higher, so the center works.” Do not soften it yet — you critique the claim as stated.
Name the claim type and the unit. Is it population or causal? “The center works” is a causal claim. The unit is the individual student (the row is one student’s end-of-term score). Note immediately that a causal claim requires either random assignment or an adjusted observational argument with stated assumptions — and this study has neither random assignment nor (in the raw claim) any adjustment.
Read off the design. Was anything assigned at random? No — students self-selected into using the center. Was anything sampled at random? Not in the comparison itself; the 120 users and 180 non-users are simply everyone observed. So the design is observational, which licenses association, not causation, until you do more work.
List the threats, most-load-bearing first. The headline threat is confounding: prior ability and motivation drive both who uses the center and who scores well, opening a backdoor path. That is why the naive gap overstates any real effect.
Compute the honest number under stated assumptions. The naive difference is \(82.0 - 74.0 = +8.0\) points. Stratifying on the pre-treatment prior-ability tier shrinks it to an adjusted \(+3.0\). The \(+5.0\) difference between them is confounding, not effect. Write the assumption out loud: the adjustment is valid only if prior ability is the confounder and it is measured well — a measured-confounder assumption.
State what the data support, narrowly. Not “the center works.” Rather: under the measured-confounder assumption, the center is associated with about a \(+3.0\)-point gain; the raw \(+8.0\) is inflated by selection on prior ability. Note the parallel, as a lesson not a guarantee: a well-run experiment recovered \(d = 3.0\) for a similar workshop, so the adjusted observational estimate is in the right neighborhood — when the confounder is measured and correct.
Name what would strengthen it. A randomized encouragement to use the center, or measuring the confounders you currently only assume, would let the causal claim be made far more confidently.
Your turn — repeat on Study E and Study S. Run the same eight steps on a one-liner from the experiment and from the survey. The next two subsections give you the locked numbers and the bounded rewrite for each.
Critiquing the experiment claim (Study E)
Raw claim: “The Focus workshop raised problem-solving gain by 3 points (p ≈ 0.06), but it wasn’t significant, so the workshop doesn’t work.” This claim is causal, the unit is the student, and the design does have random assignment — 60 students randomized 30 treatment / 30 control — so a causal reading is actually licensed here. The error in the claim is the opposite of overclaiming: it reads a borderline p-value as a verdict. The observed effect is \(d = 8.0 - 5.0 = 3.0\) points, \(\operatorname{SE}(d) \approx 1.55\), \(t \approx 1.94\), \(p \approx 0.057\) — borderline, not zero. The bounded memo says: random assignment licenses a causal read; the estimated effect is \(+3.0\) points with the interval straddling the conventional cutoff; this is weak-but-suggestive evidence the workshop helps, not evidence it does nothing. What would strengthen it is more power through a sharper design — blocking on prior-performance tier drops the residual SD from \(6.0\) to \(\approx 4.0\), giving \(\operatorname{SE} \approx 1.03\) and \(p \approx 0.005\) on the same \(d = 3.0\). The memo’s lesson: a non-significant result from a small, unblocked experiment is not the same as no effect (Risk 5 in reverse).
Critiquing the survey claim (Study S)
Raw claim: “A campus poll shows 45% of undergraduates get adequate sleep.” This is a population claim, the unit is the student, and the design has random sampling (an SRS of \(n = 600\)) — so a population claim is on the right footing, up to two threats the one-liner hides. First, coverage: the frame is the registrar email list of \(11{,}400\), missing \(600\) of the \(12{,}000\) undergraduates who have no active campus email and can never be selected. Second, nonresponse: only \(360\) of the \(600\) responded (a 60% rate), and the \(240\) nonrespondents may differ systematically. The point estimate is \(\hat p = 162/360 = 0.45\) with \(\operatorname{SE} \approx 0.026\) and a 95% CI of about \((0.40, 0.50)\) — but that interval only counts sampling noise. The nonresponse bound, assuming the worst about the missing \(240\), runs \([162/600,\ (162+240)/600] = [0.27,\ 0.67]\), which dwarfs the sampling CI. The bounded memo: among emailed undergraduates who responded, 45% report adequate sleep; accounting for nonresponse, the population figure could plausibly lie anywhere from 27% to 67%, and the claim cannot be stretched past the emailed population (Risk 13). What would strengthen it is raising the response rate or following up a random subsample of nonrespondents — not a bigger sample, because nonresponse, not sample size, is the threat.
A transfer example — a news headline
Here is a claim in a brand-new context, with illustrative numbers distinct from the locked studies. A news site reports: “Our online poll of readers shows 62% of Americans support the new campus policy.” Run the skeleton. Claim type: population. Unit: a person. Design: the respondents are a self-selected online sample — no random sampling — so there is no mechanism that earns a population claim at all; this is a convenience sample. Threats: severe self-selection (people with strong opinions click), an undefined frame (readers of one site, not Americans), and unknown nonresponse. What the data support: essentially a statement about who chose to click, not about Americans. What would strengthen it: a probability sample from a defined frame with a measured response rate. The 62% is a real number attached to a claim it cannot carry — exactly the move the memo exists to catch.
Reproducible-file convention
Keep the whole workshop in one .qmd file per memo so a reader can re-run your arithmetic and see exactly how each number was produced. The R below is shown static and non-executed (a plain ```r fence, not an executable {r} cell), the way the whole site is built; copy it into your own file to run it. Any chunk that could draw randomness opens with set.seed(45403), the course seed, so a shuffle or a resample is reproducible.
Name files for the memo, not the date: memo-tutoring-center.qmd, memo-focus-experiment.qmd, memo-sleep-survey.qmd. Inside, use the memo template sections as headings so the structure is visible at a glance: Claim · Unit · Design · Threats to validity · What the data support · What would strengthen it. The arithmetic lives in one small chunk near the top so the prose can point back to named numbers.

# Week 14 — design-memo arithmetic for the three locked studies
# Static, non-executed teaching code. Synthetic data; seed set.
# All values are the bible's LOCKED numbers — do not invent or alter.
set.seed(45403)
# --- Study O: the tutoring-center observational claim -----------------
naive <- 82.0 - 74.0 # users minus non-users -> +8.0 (association)
adjusted <- 3.0 # stratify on pre-treatment prior-ability tier
confound <- naive - adjusted # +5.0 of the gap was confounding, not effect
# naive = 8.0 ; adjusted = 3.0 ; confounding inflation = 5.0
# Memo: NO random assignment -> "associated with," not "causes," and only
# +3.0 under the measured-confounder assumption (prior ability measured well).
# --- Study E: the Focus experiment claim ------------------------------
d <- 8.0 - 5.0 # treatment mean minus control mean -> +3.0 (CAUSAL: randomized)
sp <- 6.0 # pooled SD
SEd <- sp * sqrt(1/30 + 1/30) # ~ 1.55
tE <- d / SEd # ~ 1.94 ; two-sided p ~ 0.057 (borderline, not zero)
# d = 3.0 ; SE = 1.55 ; t = 1.94 ; p ~ 0.057
# Memo: random ASSIGNMENT licenses causal read; p~0.06 is weak-but-suggestive,
# NOT proof of no effect. Blocking would sharpen SE to ~1.03 (p ~ 0.005).
# --- Study S: the campus sleep-survey claim ---------------------------
phat <- 162 / 360 # 0.45 among the 360 respondents (random SAMPLING)
SEp <- sqrt(phat * (1 - phat) / 360) # ~ 0.026 ; 95% CI ~ (0.40, 0.50)
lo <- 162 / 600 # all 240 nonrespondents slept < 7h -> 0.27
hi <- (162 + 240) / 600 # all 240 slept >= 7h -> 0.67
# phat = 0.45 ; SE = 0.026 ; sampling CI ~ (0.40, 0.50)
# nonresponse bound [lo, hi] = [0.27, 0.67] -- DWARFS the sampling CI
# Memo: population claim only up to coverage (frame 11,400 < 12,000) and
# nonresponse; do not stretch past the emailed population (Risk 13).Each printed value here is the design move in arithmetic form. The +8.0 versus +3.0 is confounding made visible — what was observed minus what is plausibly causal once you close the backdoor. The p ~ 0.057 on a genuinely randomized d = 3.0 is a borderline causal estimate, not a null verdict. The [0.27, 0.67] bound is nonresponse made visible — the honest width of a population claim once you stop assuming the missing 240 look like the responding 360. Your memo’s prose should name each of these in a sentence, never just print the number.
Debugging
The most common way a critique fails is diagnosing the wrong threat — writing a long paragraph about sample size when the real problem is selection or nonresponse. The symptom is a memo whose “what would strengthen it” section says “collect more data,” because more data is the reflexive fix for everything and the correct fix for almost nothing here. The cure is mechanical: run the design fork first. Ask “was it assigned? was it sampled?” before you say a word about \(n\). If the tutoring-center gap is confounded, a sample of a million self-selected users still gives a biased \(+8.0\) — more data sharpens a wrong number. If the sleep survey’s threat is the 240 nonrespondents, doubling the sample to 1,200 with the same 60% rate just gives you 480 nonrespondents and the same \([0.27, 0.67]\)-style bound. Sample size is the threat only when the design is otherwise clean and the interval is honestly the sampling interval.
A second failure mode, specific to this week’s traps: the memo’s verb outruns its design. You write “the center improved scores” (a causal verb, Risk 15) from an observational gap, or you write “Americans support the policy” (Risk 13) from one campus’s email list. The fix is a search-and-replace discipline before you submit the memo to yourself: highlight every causal verb (causes, raises, improves, works) and every population noun (Americans, undergraduates, students), and for each one ask, does the design earn this exact word? If random assignment is absent, downgrade the verb to “is associated with.” If the frame is narrower than the noun, narrow the noun to the frame. The diagram and the memo encode assumptions, not conclusions — every causal arrow you let stand must be justified by the design or by stated domain knowledge, not by the size of a p-value.

AI Use Note
A language model is a useful drafting and stress-testing partner for a critique, and a dangerous oracle for a number. It will happily produce a confident, fluent memo with a fabricated effect size and a causal verb the design cannot support. Use it for structure and challenge; verify every claim and every number yourself against the locked study values and the design fork.
| Tool | Purpose | Verification |
|---|---|---|
| LLM chat assistant | Draft a first pass of the memo’s six sections from your bullet notes; suggest threats you may have missed | Re-derive every number from the static R above; confirm the claim type, unit, and design fork by hand — the model invents effect sizes and softens causal language |
| LLM as red-team critic | Ask it to attack your memo: “what claim here outruns the design?” to surface Risk 13 / Risk 15 slips | Treat each objection as a hypothesis; accept only the ones you can trace to a named threat in the design, discard confident-but-wrong ones |
| Grammar / style checker | Tighten the memo’s prose and enforce hard-wrapping and the en-dash house style | Style only; it will not catch a causal verb that outruns an observational design — that check stays human |
The rule is the course’s rule for software generally: the tool can shape the sentence, but the claim is yours, and the claim must be no larger than the design can carry.
Reading and source pointer
This week is grounded in the instructor notes (primary) — the critique framework (claim → unit → design → threats → what the data support → what would strengthen it) and the design-memo template are course-original — and in Statistical Inference via Data Science (ModernDive; Ismay, Kim & Valdivia) for the reproducible reporting workflow and the one-file .qmd posture. ModernDive is OER under CC BY-NC-SA 4.0. These notes are the course’s own synthesis, grounded in but not copied from the sources. No prose, examples, exercises, or figures are reproduced; the memo template and every worked critique here are written for this course.
Public vs. graded
These notes, the examples, and the practice here are public and ungraded — study material only. No graded prompts, answer keys, rubrics, point values, or due dates appear on this site. Graded design checkpoints, weekly quizzes, design memos and homework, applied design labs, the midterm, the final design project, and the final exam live in Blackboard (the LMS), which is authoritative for due dates, submissions, and grades. If this page and Blackboard ever disagree, follow Blackboard.
Portfolio connection
The design memo is the keystone of your course portfolio. Every concept week fed one piece of it: Week 3 taught you the sampling-versus-assignment fork that opens every critique; Week 4 and Weeks 9–10 gave you confounding, adjustment, and the backdoor reasoning behind Study O’s \(+8.0 \to +3.0\); Weeks 5–8 gave you the experimental designs and the interaction-versus-main-effect reading; Weeks 11–13 gave you coverage, the nonresponse bound, and the missing-data mechanisms. This workshop is where those threads become a single written artifact. Keep your three bounded memos — tutoring center, Focus experiment, sleep survey — in your portfolio; they are the working draft of the final design project, which asks you to critique or design one study and write the memo in full. A strong portfolio shows the same disciplined move applied across an experiment, an observational study, and a survey: the claim named, the design read, the threats listed, and the conclusion kept no larger than the design can carry.
See also
- Week 13 — Missing data and nonresponse — the nonresponse bound \([0.27, 0.67]\) and the MCAR/MAR/MNAR vocabulary your survey critique leans on
- Week 15 — Final design memo and review — where this miniature becomes the full final design memo and the whole arc is seen as one picture
- Week 9 — Observational studies and Week 10 — Causal diagrams and backdoor reasoning — the adjustment and Risk-15 reasoning behind the tutoring-center memo
- Design glossary — the fixed vocabulary every memo uses
- Design reference — the design families side by side, for the “design” line of a critique
- Causal diagram guide — drawing the arrows a causal memo must justify