Week 12 — Classical hypothesis testing
MATH 21003 · Introduction to Statistical Methods · Fall 2026 · Week 12 (Nov 9–13, 2026)
Why this week matters
Last week we answered the two questions of inference — could this be chance? and what values are plausible? — by simulation: we let the computer act out “no effect” thousands of times and read the answer off a picture. That is the most honest way to see inference. But it is not how most results in journals, software, and reports are actually computed. Those use a classical formula — a normal or \(t\) curve — that arrives at the same answer without the thousands of simulations. This week we learn that formula, and the whole point is that it is a shortcut to last week’s simulation, not a new idea. We will prove it to ourselves on the very same studies. The rhythm: Monday re-runs the opportunity-cost study with the formula and names the classical objects — null, test statistic, p-value. Wednesday reads real software output: a proportion \(z\)-test and \(t\)-tests for means. Friday steps back to ask how a test can be wrong — Type I and Type II errors — and ties the formula back to the simulation.
Monday: the same answer, by formula
Bring back the opportunity-cost study. Reminding students that they could keep their money raised the “did not buy” rate by
\[\text{estimate} = \frac{34}{75} - \frac{19}{75} = 0.20,\]
and last week 1,000 simulated shuffles gave a p-value of about \(0.006\). Now the formula. Instead of simulating the spread of the null distribution, the classical method computes it. The spread of a statistic from sample to sample has a name — the standard error (SE) — and for this difference in proportions the SE works out to about \(0.078\). (Think of the SE as the typical wobble we watched the bootstrap and null distributions produce; the formula just calculates it instead of showing it.)
With the SE in hand we measure how far the observed estimate sits from the null value of “no effect” (\(0\)), in standard-error units:
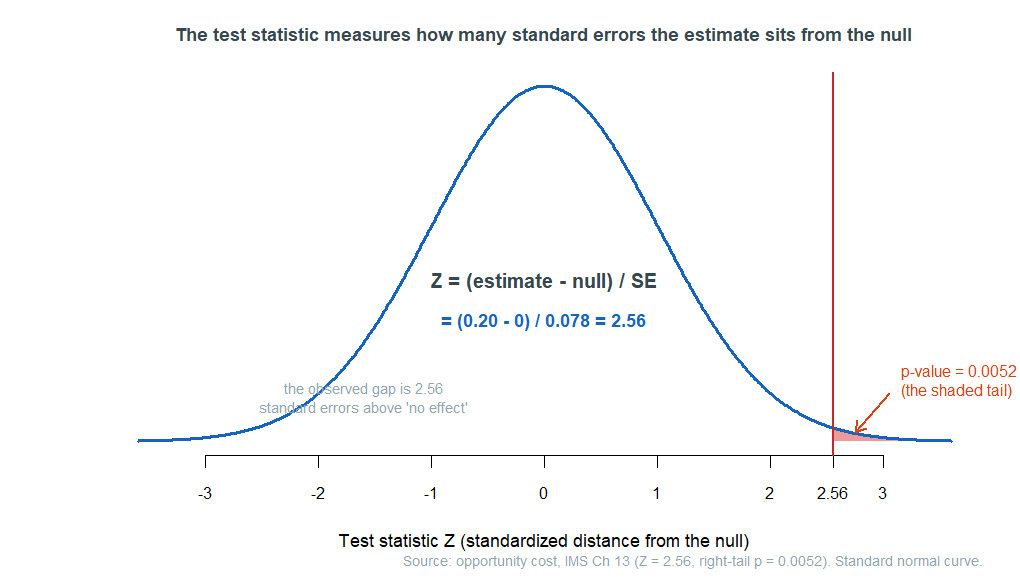
\[Z = \frac{\text{estimate} - \text{null}}{\text{SE}} = \frac{0.20 - 0}{0.078} = 2.56.\]
This \(Z\) is the test statistic: the observed gap is \(2.56\) standard errors above zero. Under the usual large-sample conditions, the Central Limit Theorem supports an approximate normal model for a statistic like this — so the null distribution is approximately a smooth normal curve, and we no longer need to draw it by simulation. The p-value is the tail beyond \(Z = 2.56\) on that curve: \(p = 0.0052\). Compare:
| Method | p-value |
|---|---|
| Week 11 simulation (1,000 shuffles) | \(\approx 0.006\) |
| Week 12 normal-model formula | \(0.0052\) |
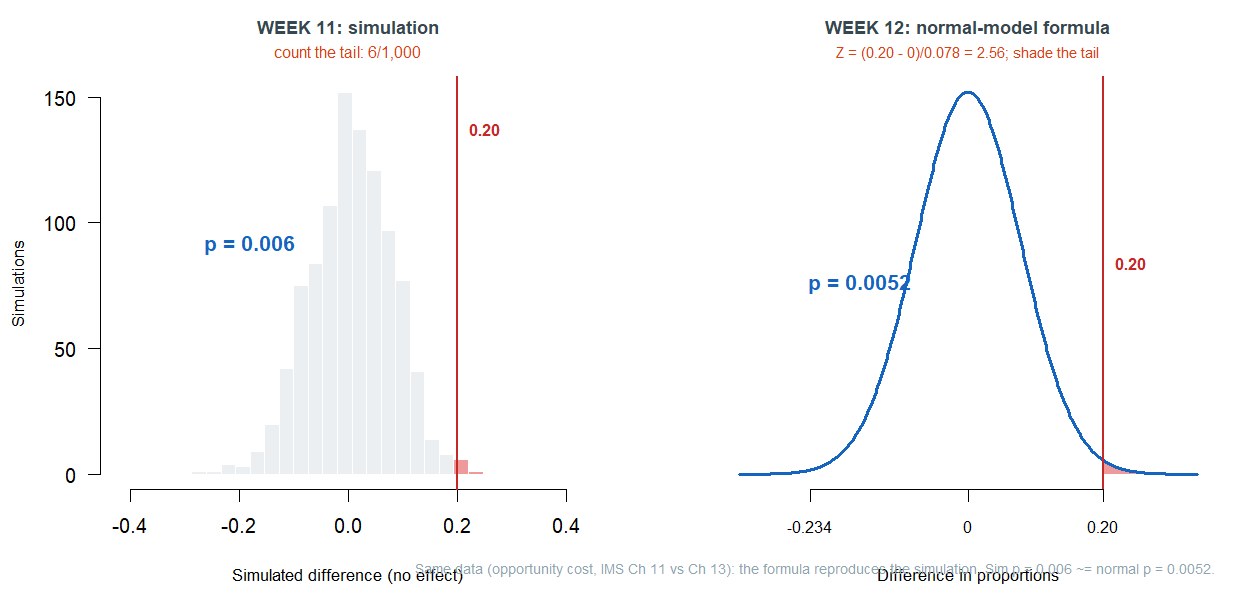
The two pictures are the same story told two ways. The simulation builds the null distribution; the formula assumes its shape is normal and reads the tail. When the assumption holds, they agree — and that agreement is the entire justification for the classical shortcut.
Monday, continued: null, test statistic, p-value as classical objects
Now the vocabulary, stated once and reused all week. A classical test has four pieces:
- The null hypothesis \(H_0\): the skeptic’s “nothing is going on” (no effect, no difference, parameter equals some null value). For opportunity cost, \(H_0\): the reminder makes no difference (the true difference in proportions is \(0\)).
- The alternative hypothesis \(H_A\): what we would conclude if the evidence is strong (an effect exists). It can be one-sided (a difference in a stated direction) or two-sided (a difference in either direction); two-sided is the cautious default.
- The test statistic, \((\text{estimate} - \text{null})/\text{SE}\), which standardizes the result into “how many SEs from the null.” For proportions and large samples this is a \(z\); for means it is a \(t\) (next section).
- The p-value, the area in the tail(s) of the model curve beyond the test statistic — the chance, if \(H_0\) were true, of a result this extreme.
We compare the p-value to a significance level \(\alpha\) (commonly \(0.05\)) and reject \(H_0\) when \(p < \alpha\). The traditional name for clearing that bar is statistically significant; IMS sometimes writes statistically discernible for the same idea, but we will say significant.
Monday’s honest footnote: when the shortcut is loose
The formula is an approximation, and approximations have limits. Take the medical-consultant case from last week: \(\hat p = 3/62 = 0.048\) complications against a national rate of \(10\%\). The normal-model test gives \(Z = (0.048 - 0.10)/0.038 = -1.37\) and a p-value of \(0.0853\). But last week’s simulation gave about \(0.1222\) — noticeably larger. The normal model is too optimistic here, because with only \(62\) surgeries and a small proportion the true null distribution is skewed, not the symmetric bell the formula assumes. The lesson cuts both ways: the formula usually reproduces the simulation (opportunity cost), but when the sample is small or the proportion is near \(0\) or \(1\), trust the simulation. The two methods agreeing is reassuring; the two methods disagreeing is a warning about the formula’s assumptions.
The standard error and the confidence interval
The same \((\text{estimate}, \text{SE})\) pair that powers a test also builds a confidence interval — the classical version of last week’s bootstrap interval. Instead of reading percentiles off a bootstrap distribution, we go a fixed number of standard errors out from the estimate:
\[\text{estimate} \pm z^\star \times \text{SE},\]
where \(z^\star = 1.96\) (about \(2\)) for \(95\%\) confidence, \(1.65\) for \(90\%\), and \(2.58\) for \(99\%\). The quantity \(z^\star \times \text{SE}\) is the margin of error. For the stent study, the estimated increase in 30-day stroke risk was \(0.090\) with \(\text{SE} = 0.028\), so
\[0.090 \pm 1.96 \times 0.028 = (0.035,\ 0.145).\]
We are \(95\%\) confident the true increase is between \(3.5\) and \(14.5\) percentage points. Because the interval lies entirely above zero, “no effect” is not a plausible value — the stent increased risk. That is the duality between tests and intervals: a \(95\%\) interval that excludes the null value corresponds to a two-sided test that rejects at \(\alpha = 0.05\), and an interval that contains the null corresponds to a test that fails to reject. The interval does double duty — it gives a decision and a set of plausible values, the two questions of inference in a single line.
Wednesday: reading a \(t\)-test and a proportion-test output
In practice you will rarely compute these by hand; you will read software output. Two small wrinkles first. For a proportion, the test statistic is a \(z\) and the curve is the normal — e.g., a payday-loan poll of \(n = 826\) with \(\hat p = 0.51\) tested against \(p_0 = 0.50\) gives \(Z = (0.51 - 0.50)/0.017 = 0.59\), a one-sided \(p = 0.2776\): nowhere near significant, so we fail to reject. For a mean, the SE must be estimated from the data’s own spread, which adds a little extra uncertainty, so we use a \(t\)-distribution instead of the normal. The \(t\) looks like the normal but with slightly thicker tails; the smaller the sample, the thicker, and for large samples the two are indistinguishable. Each \(t\) comes with degrees of freedom (df), roughly the sample size minus one — you read it off the output, you do not look it up in a table.
Here are two real outputs, annotated for reading:

Read the left panel — a one-mean \(t\) for mercury in \(19\) Risso’s dolphins — as an estimation problem: the mean is \(\bar x = 4.4\) micrograms per gram, and the \(95\%\) interval \((3.29, 5.51)\) is the range of plausible values for the true mean. Read the right panel — a two-mean \(t\) comparing birth weights of babies born to nonsmokers versus smokers — as a test: the observed difference is \(0.40\) lb, \(t = 1.54\) on about \(89\) df, and \(p = 0.138\). Because \(0.138 > 0.05\) we fail to reject \(H_0\): in this sample there is no detectable difference. (Notice how the same machine handles one mean, two means, and a proportion — only the SE formula and the curve change.) The skill for the week is exactly this: find \(H_0\), read the estimate, the test statistic, the df, the p-value, and the CI, and write a conclusion in context — not just “reject” or “fail to reject.”
Friday: when a test goes wrong — Type I and Type II errors
A test ends in a yes/no decision about \(H_0\), and the truth is also yes/no, so there are exactly two ways to be wrong:

A Type I error is rejecting a true null — a false alarm, declaring an effect that isn’t there. A Type II error is failing to reject when the alternative is actually true — a missed real effect. The connection to the significance level is exact: \(\alpha\) is the long-run Type I error rate. Choosing \(\alpha = 0.05\) means accepting that, when nothing is going on, we will cry “effect!” about \(5\%\) of the time. If a false alarm is costly we set \(\alpha\) smaller (\(0.01\) or \(0.001\)); if missing a real effect is costlier we may allow a larger one. The two errors trade off — squeezing one tends to inflate the other — which is why you cannot drive both to zero.
The flip side of a Type II error is power: the probability of correctly rejecting \(H_0\) when there really is an effect. Power rises with a larger true effect and a larger sample size — bigger signals and more data are both easier to detect. (We treat power conceptually only; there is no formula to memorize here.)
A worked decision: the CPR study compared survival after a blood thinner. Survival was \(11/50 = 0.22\) in the control group and \(14/40 = 0.35\) in the treatment group, a difference of \(0.13\) in favor of treatment. Because the researchers had no prior direction, they ran a two-sided test and got a p-value of \(0.262\) — far above \(0.05\) — so they failed to reject \(H_0\): no convincing evidence of a survival effect. That conclusion is honest, but note the risk: if the thinner truly helps, “fail to reject” would be a Type II error, a missed effect a larger study might catch. “No significant difference” is never the same as “no difference.”
One discipline this makes vivid: decide your hypotheses before you see the data. Peeking and then switching a two-sided test to whichever one-sided version “works” quietly doubles your Type I error rate from \(5\%\) to \(10\%\) — you have given chance two bites at the apple.
A note on regression inference (closing the Week 9 loop)
Back in Week 9 we read a regression output and greyed out the “Std. Error / \(t\) / p-value” columns, promising to return. This is the return, and it is short: those columns are exactly this week’s idea applied to a slope. Each slope estimate has a standard error, a test statistic of the same \((\text{estimate} - \text{null})/\text{SE}\) form (with a null value of \(0\), meaning “this predictor has no association with the outcome once the others are held constant”), a p-value, and a confidence interval. So a slope’s p-value answers the familiar question — could this association be chance? — and its CI gives plausible values for the slope. That is all you need to read a regression’s inference columns; the machinery for computing them is a later, more-advanced topic and is not part of this course.
Common mistakes
- “The p-value is the probability the null is true.” Still no — it is the probability of data this extreme if \(H_0\) is true. The classical curve does not change that.
- “Fail to reject means the null is true.” It means not enough evidence against it. The CPR study failed to reject, but a real effect could still exist (a Type II error).
- “Statistically significant means the effect is large or important.” A test rules out chance; it says nothing about size. With a big enough \(n\), a trivial effect can be significant.
- “Use a \(z\) for everything.” Means use a \(t\) (estimated SE, thicker tails); proportions use a \(z\). Read which one the output reports.
- “Pick the hypothesis direction after seeing the data.” That inflates the Type I error rate. Set \(H_0\) and \(H_A\) first.
- “The confidence interval and the test are different analyses.” They are two faces of one thing: an interval excluding the null value matches a test that rejects.
What you should be able to do by Friday
By the end of Week 12 you should be able to:
- state a null and alternative hypothesis for a study, and tell one-sided from two-sided;
- explain the test statistic \((\text{estimate} - \text{null})/ \text{SE}\) as “how many standard errors from the null,” and the p-value as a tail area of the model curve;
- read a proportion \(z\)-test, a one-mean \(t\), and a two-mean \(t\) output — finding \(H_0\), the estimate, the statistic, the df, the p-value, and the CI — and conclude in context;
- build and read a confidence interval as \(\text{estimate} \pm z^\star \times \text{SE}\), and use the test–interval duality;
- name and distinguish Type I and Type II errors, explain \(\alpha\) as the Type I error rate, and describe power conceptually;
- explain why the classical formula reproduces last week’s simulation — and when (small \(n\), skew) it may not.
Assignments this week
- Monday check. A short in-class concept check on stating the null and identifying the test statistic (and matching the formula to last week’s simulation idea). Plan for about 3–5 minutes. Sheet: Week 12 Monday exit ticket.
- Wednesday check. A short application reading a \(t\)-test or proportion-test output: state \(H_0\), read the p-value and CI, and conclude in context. Plan for about 8–12 minutes. Sheet: Week 12 Wednesday exit ticket.
- 🔒 Friday quiz — handled through Blackboard or in class as directed. The quiz prompt is not posted here. Timing and submission details live in Blackboard.
- 🔒 Homework 6 (biweekly, Weeks 11–12) — posted and submitted through Blackboard. It spans last week and this one, including a bridge problem that runs one case study by both simulation and formula; due near the start of the following week.
Read more in IMS / ISLBS
The course page above is the main explanation for this week. For a second voice at similar depth:
- IMS — Introduction to Modern Statistics, Chapter 13 Inference with mathematical models (the normal model as the shortcut, the standard error and margin of error, and the opportunity-cost, medical-consultant, and stent case studies) and Chapter 14 Decision errors (Type I and Type II errors, the significance level as an error rate, two-sided tests, and power). For the applied output reading, Chapters 16, 19, and 20 give the one-proportion \(z\), one-mean \(t\), and two-mean \(t\) examples. Read the worked examples and output; skip the by-hand derivations and conditions — we read results, we do not derive them.
OpenIntro book page: https://www.openintro.org/book/ims/ - ISLBS — Introductory Statistics for the Life and Biomedical Sciences, Chapter 4 §4.3 (the five-step hypothesis-test framework, the test–interval duality, and decision errors) and Chapter 5 Inference for numerical data, §5.1–§5.3 (one-sample, paired, and two-sample \(t\)-tests on clinical data — dolphin mercury, the wetsuit swim study, and birth weight by smoking). The clinical \(t\) outputs are your second voice for Wednesday. You can skip §5.4 (power calculations) and §5.5 (ANOVA), which are beyond this course.
OpenIntro book page: https://www.openintro.org/book/biostat/
Looking ahead: Week 13 extends the test-and-interval tools from one proportion or one mean to comparing proportions on two-way tables — relative risk, odds, and the chi-square idea. Those are next week’s business; this week stops at a single proportion and at means.
Sources adapted in this lesson: This page draws primarily on OpenIntro Introduction to Modern Statistics (2e), Çetinkaya-Rundel & Hardin: Chapter 13 for the normal-model shortcut, standard errors, margins of error, and the opportunity-cost, medical-consultant, and stent examples; Chapter 14 for decision errors, significance levels, two-sided testing, and power; and Chapters 16, 19, and 20 for applied one-proportion \(z\), one-mean \(t\), and two-mean \(t\) output reading. It also draws on OpenIntro Introductory Statistics for the Life and Biomedical Sciences, Vu & Harrington, Chapter 4 §4.3 and Chapter 5 §5.1–§5.3 for the clinical hypothesis-test framework and the one-sample, paired, and two-sample \(t\)-test examples. OpenIntro materials are CC BY-SA 3.0. Source files: IMS and OI-Biostat. The public figures are course-built reconstructions or schematics using the source-grounded values documented in the Week 12 extraction notes.